
機械学習関連の記事を見ていると多くの記事が既存のデータセットを使って機械学習をしています。
確かにデータセットを使えば手軽に機械学習を始められるのですが、自分で集めたり作成したりしたデータを使った方が体系的に機械学習について学ぶことができる気がします。
ということで今回は機械学習で使うサンプルデータを作成してみようと思います。
機械学習で使うサンプルデータを作成してみよう
はじめに
・今回作成するのは男性と女性の(身長, 体重)という形で表されるサンプルデータです。
・それぞれの正解ラベルについては男性の場合は0を、女性の場合には1をラベリングします。
なおデータ作成に際し、東京農業工業大学の「2012健康診断データ」というものを参考にしました。
データの作成
ここからは実際にサンプルデータを作成していきます。
参考にした健康診断のデータによると男女の平均身長と平均BMIは以下のようになっています。
| 男性 | 身長(cm) | BMI |
|---|---|---|
| 平均 | 171.4 | 21.3 |
| 標準偏差 | 5.69 | 2.95 |
| 女性 | 身長(cm) | BMI |
|---|---|---|
| 平均 | 158.8 | 20.4 |
| 標準偏差 | 5.23 | 2.39 |
上記データを使って以下の式で(身長, 体重)のサンプルデータを作成します。
height = numpy.random.normal(身長の平均, 身長の標準偏差, 作成するデータ数)
BMI = numpy.random.normal(BMIの平均, BMIの標準偏差, 作成するデータ数)
weight = (height * 0.01) ** 2 * bmi・BMIを使う理由は身長と体重を紐づけるためです。
・BMI = 体重kg ÷ (身長m)2という式でBMIは求められるので、この計算式を使って体重を計算しています。
ということでこれらを使って男女それぞれの身長と体重を500データずつ、計1000データ作成しましょう。
以下実装コードです。
import numpy as np
n = 500
m_height = np.random.normal(171.4, 5.69, n)
f_height = np.random.normal(158.8, 5.23, n)
m_bmi = np.random.normal(21.3, 2.95, n)
f_bmi = np.random.normal(20.4, 2.39, n)
m_weight = (m_height*0.01)**2 * m_bmi
f_weight = (f_height*0.01)**2 * f_bmi
male = []
female = []
for i in range(n):
male.append((m_height[i], m_weight[i]))
female.append((f_height[i], f_weight[i]))
print(male[0])
print(female[0])
# 実行結果
# (170.54614126453677, 58.5925767997735)
# (155.82665716408383, 49.74398289043511)これで男性と女性の(身長, 体重)というサンプルデータがmaleとfemaleという変数に格納することができました。
最後に正解ラベルを用意する必要があるのですが、正解ラベルについては次のような簡単なコードで作成できます。
male_label = [0] * n
female_label = [1] * n以上の手順で機械学習で使えるサンプルデータを作成することができました!
(ついでに)データの可視化
せっかくサンプルデータを作成したので実際に散布図に表してみましょう。
以下実装コードと実行結果です。
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
m_height = np.random.normal(171.4, 5.69, 500)
f_height = np.random.normal(158.8, 5.23, 500)
m_bmi = np.random.normal(21.3, 2.95, 500)
f_bmi = np.random.normal(20.4, 2.39, 500)
m_weight = (m_height*0.01)**2 * m_bmi
f_weight = (f_height*0.01)**2 * f_bmi
male = []
female = []
for i in range(500):
male.append((m_height[i], m_weight[i]))
female.append((f_height[i], f_weight[i]))
# グラフの描画
plt.scatter(m_height, m_weight, c="blue", label="male")
plt.scatter(f_height, f_weight, c="red", label="female")
plt.legend()
plt.xlabel("height")
plt.ylabel("weight")
plt.show()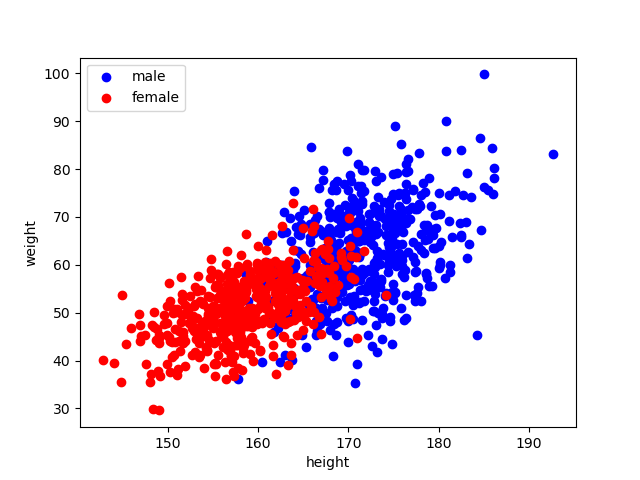
多少の外れ値はあるものの、男女の身長と体重について大体の傾向がグラフからも確認することができました。
まとめ
今回はPythonを使って機械学習で使うサンプルデータを作成しました。
次回は実際に今回作成したサンプルデータを使って機械学習をしていきたいと考えています。それではまた!










コメント